논문리뷰 (1) 에서 이어짐.

* 이 글은 공부하면서 메모하는 글으로 틀린 내용이 있을 수 있습니다.
정보 습득의 목적으로 읽기 적합하지 않습니다.
Anchor-free
YOLOv4 및 YOLO v5는 모두 앵커 기반 파이프라인을 따릅니다. 하지만 이에는 2가지 문제가 있습니다. 첫째, 훈련 전에 최적의 앵커 세트를 결정하기 위하 클러스터링 분석을 수행해야 합니다. 둘째, 앵커 기반 예측은 복잡성 증가로 인해 병목 현상이 발생할 수 있습니다.
앵커 기반 매커니즘은 설계 매개변수를 줄여 검출, 트레이닝 및 디코딩 단계를 간소화하여 우수한 성능을 보입니다.
💡 공부 Anchor based model 과 Anchor free model
[anchor-free detectors]
앵커-프리 디텍션을 공부하기 전에 먼저 Anchor based detection 에 대해 공부해 보았다.
- 객체의 크기, 비율 등 객체의 특징에 해당하는 B개의 anchor box를 사람이 디자인
- 이미지 전체를 S*S 그리드로 나누고 각 grid 에서 디자인한 B개의 anchorbox 에 해당하는 feature를 모아 네트워크에 넣어주는 방식
- 이후 anchor box 마다 객체일 확률, 배경일 확률 등을 예측하고 세부 조정한다
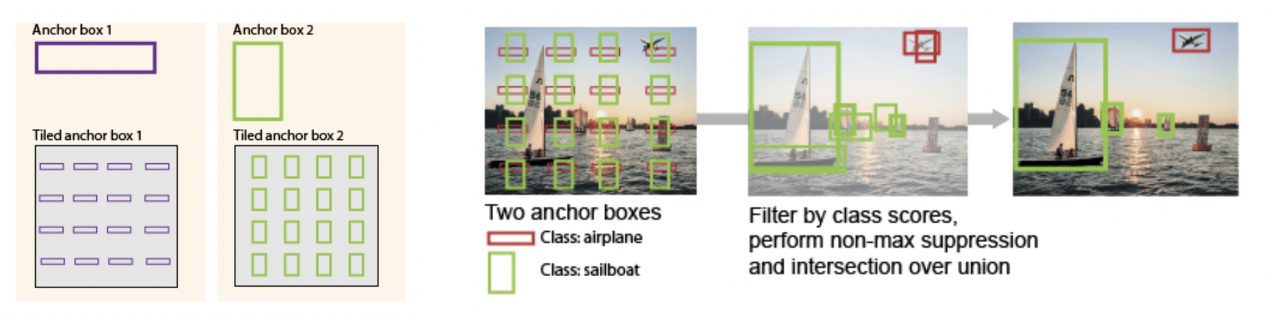
[anchor based detection 한계]
- 데이터가 바뀔 때 마다 매번 BOX 를 설계해줘야한다.
- 학습 데이터에 포함되지 않은 특징을 가진 데이터를 예측할 때 성능이 떨어진다.
- 다양한 크기, 비율 탐지 위해 2개 이상의 Anchor 를 사용한다
: 각 Anchor 에서 만들어내는 feature가 많아지면 과부화
여러 알고리즘에서 앵커를 비교한 표 (출처: https://csm-kr.tistory.com/33)
| Algorithm | Number of Anchors | Image resolution |
| YOLOv2 | 845 | 300 x 300 |
| SSD | 8732 | 416 x 416 |
| YOLOv3 | 10647 | 416 x 416 |
| Faster RCNN | 20646 | 600 x 1000 |
| RetinaNet | 67995 | 600 x 600 |
anchor free detection의 두 가지 방법 .
1. Keypoint-based method.
먼저 정의된 여러 키포인트를 위치시킨 다음 바운딩 박스를 생성하여 객체를 검출한다.
- CornerNet : 바운딩 박스를 한 쌍의 키포인트(좌측 상단 및 우측 하단 코너)로 검출
- ExtremeNet : 4개의 극점(최상위, 최좌하위, 최하상위) 및 1개의 중심점을 검출
- CenterNet : 정밀도와 회상 모두를 향상시키기 위해 키포인트들의 쌍이 아닌 삼중항으로서 CorNet을 확장
2. Center-based method.
객체의 중심점이라고 생각되는 지점을 예측. Center 부터 경계선까지의 거리를 Regression

💡 공부 anchor based detection 과 anchor free detection비교
관련논문 : Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection [링크]
위 논문에서는 앵커 기반의 RetinaNet 과 앵커 프리 기반의 FCOS 를 채택하여 차이점을 비교한다.
1. Classification 에서의 차이
(a) RetinaNet 은 IoU를 활용하여 서로 다른 피라미드 레벨의 앵커박스를 positives 로 구분한다.
공간 차원과 스케일 차원에서 동시에 positive 를 선택한다.
(b) FCOS 는 Spartial 차원에서 후보를 찾고, Scale 차원에서 사용하여 최종적으로 positives 를 구분한다.
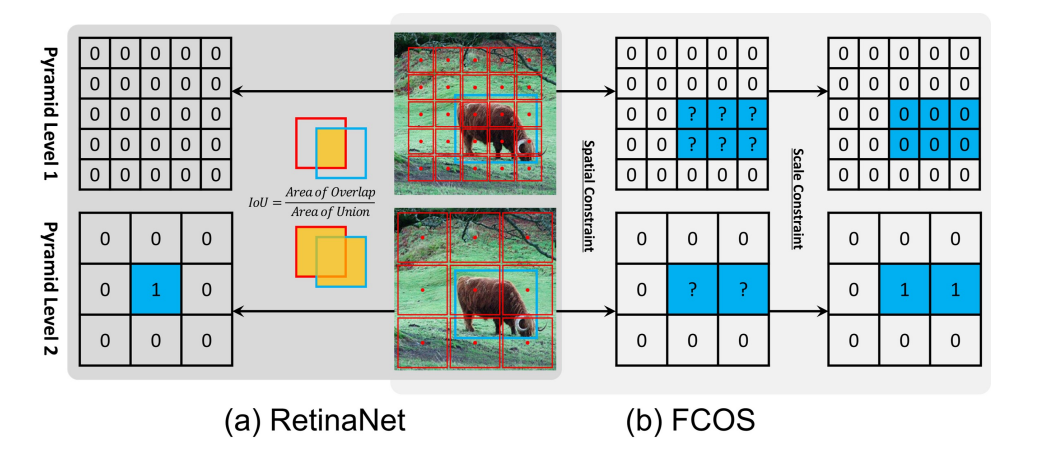
2. Regression 에서의 차이
(b) RetinaNet 은 앵커 박스와 물체 박스 사이에 오프셋이 4개인 앵커 박스에서 회귀
(c) FCOS 는 거리가 4개인 앵커 포인트에서 물체의 경계까지 회귀한다
* 단, 최종 성능, 즉 37.0% 대 36.9%, 37.8% 대 37.8%의 뚜렷한 차이가 없다
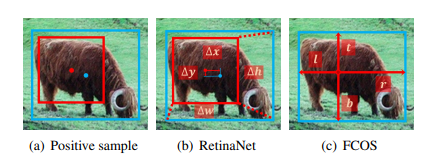
*FCOS (Fully Convolutional One-Stage object detection)
: fc layer 없이 convolutional layer 로만 구성
: Bounding Box 안에 픽셀의 좌표가 포함되면 해당 물체로 Classification을 진행
:중심으로부터 bounding box 경계까지 얼만큼 거리인지를 Regression
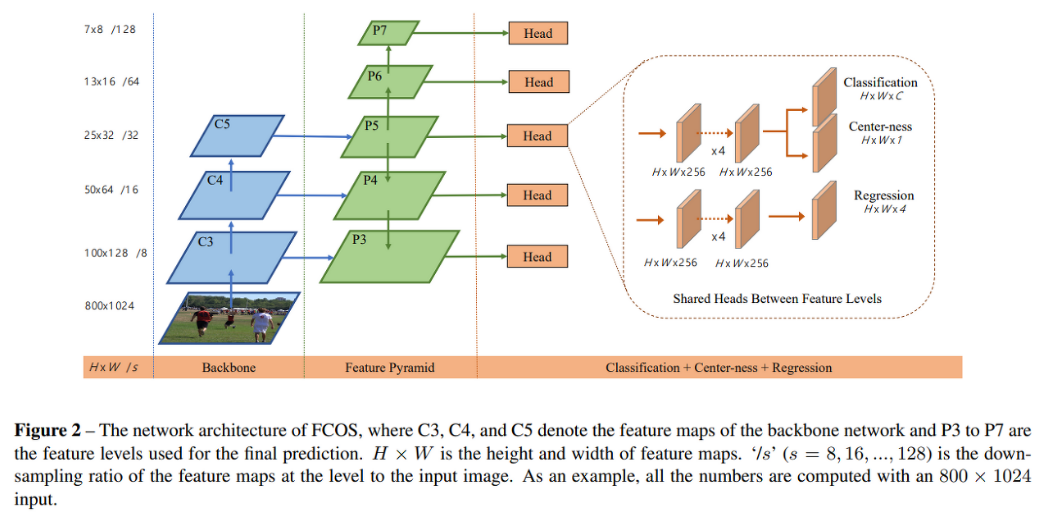
YOLO X 가 앵커박스 문제를 해결하는 방법
참고링크 : https://medium.com/mlearning-ai/yolox-explanation-how-does-yolox-work-3e5c89f2bf78
앵커상자로부터 오프셋을 예측하는 대신 모델이 bbox 를 직접 예측하도록 한다. 모델이 예측할 3가지 스케일을 기반으로 이미지를 분할한다. 각 예측을 각 그리드의 교차점에 할당한다. 이 교차점을 '앵커 포인트' 라고 한다 (Anchor based detection의 Anchor 와는 다르다. 포인트 예측을 위해 x, y 좌표를 이동하기 위한 오프셋이다 )
예) 256 * 256 이미지에 32 stride 를 적용하면 256 / 32 = 8 총 64개의 앵커 포인트가 나온다.

Multi positives
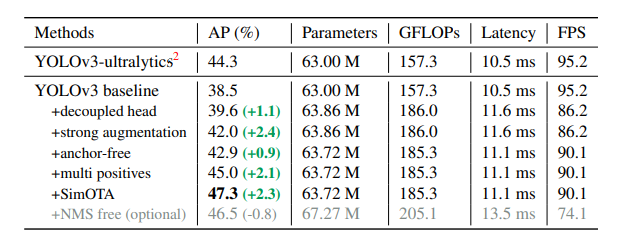
: Single positive의 경우 bbox의 중심이 있는 앵커만 positive로 평가하고 품질이 높더라도 다른 샘플은 무시합니다.
Multi Positive 는 데이터 불균형을 해소하기 위해 고안되었습니다. Single Positive의 경우 16×16=256 앵커가 있고 bbox 가 3개 있다면 Positive : Negateve = 3 : 253 의 현저한 불균형이 나타납니다. 하지만 실제로 bbox 는 복수의 앵커에 걸쳐 있는 경우가 많기 때문에 근처 3*3 앵커도 Positive 로 간주해도 문제가 없을 것이다. 만약 bbox 간의 중첩이 없는 경우 P:N = 27 : 229가 되어 데이터 불균형이 해소됩니다.
참고링크 : https://qiita.com/koshian2/items/af032cb102f48e789e66

SimOTA : 발전된 label assignment 기법

💡 공부
OTA (Optimal Transport Assignment: 전역 컨텍스트 레이블 할당을 처리
: OTA 관련 논문:Optimal Transport Assignment for Object Detection(2021) [링크]
https://medium.com/mlearning-ai/yolox-explanation-simota-for-dynamic-label-assignment-8fa5ae397f76
이 모든 과정을 처리하면
end-to-end(NMS-free) detectors
* End-to-end 방식 : 객체 검출 파이프라인이 하나의 신경망으로 구성되어 있는 경우
* NMS ( Non-maximum Suppression) 최대가 아닌 바운딩 박스를을 삭제하는 알고리즘
end to end 방식을 사용했을 때 성능과 추론 속도가 감소했다. 따라서 최종 모델에는 포함되지 않았다.

'AI SCHOOL' 카테고리의 다른 글
| 부트캠프 4개월 차의 부트캠프 선택 팁 (1) | 2023.10.31 |
|---|---|
| [YOLO X 공부] 논문 리뷰 (1) (1) | 2023.10.26 |
| [Python] 주성분 분석(Principal Component Analysis, PCA) (0) | 2023.08.28 |
| [Python] 문자열 속에서 단어 찾기 (0) | 2023.08.09 |
| [Python] 문자열을 거꾸로 출력하기 (0) | 2023.08.08 |

